
[ML] Text-to-Image Generator(1)
Architecture
The text encoding step may be performed with a recurrent neural network such as a long short-term memory (LSTM) network, though transformer models have since become a more popular option.
-> RNN:
-> LSTM:
-> transformer models:
For the image generation step , conditional generative adversarial networks have been commonly used, with diffusion models.
-> diffusion models: Diffusion Models are a class of generative models, meaning that they are used to generate novel data, often images. 노이즈를 제거하면서 학습을 한다.
diffusion model == the noise prediction model
주로 U-Net 사용

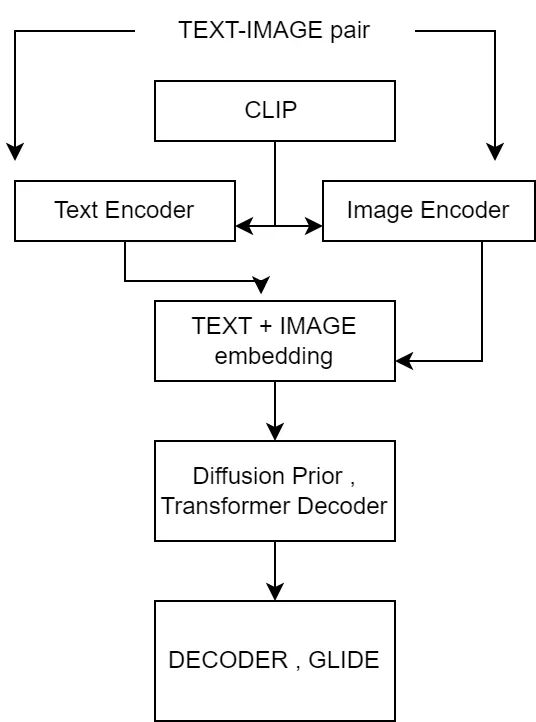
Architecture Overview
Text Encoder : To encode text data into text embeddings
Prior: Using text embeddings , generate image embeddings (the bridge)
Decoder: Generating image using image embeddings
DALL-E
Background

문장 전체에 대해 인코딩을 하고 이미지를 생성했는데, 이렇게 된다면 word 레벨에서 정보가 소실될 수 있는 단점이 있다.
따라서 word 레벨의 정보까지 사용하여 이미지를 만드는 네트워크가 Attentional Generative Network 이다.
DASAM에서는 이미지의 일부와 문장의 일부를 매핑한 후, 유사도를 계산한다.

- e: local text
- e : global text
- f: local feature
- f : global feature
Methodology
- stage1:
- Discete VAE 를 이용해서 256*256 RGB 이미지를 32*32 Image Token으로 압축
- stage2:
- 최대 256 BPE-encoded text toekns을 32*32 Image Token과 Concatenate
- Text & Image token의 결합 분포 Modeling 하는 Autoregressive transformer 학습

댓글남기기