
[ML] Object Detection & Segmentation(1)
용어 정리
- stride: 필터를 몇 칸 이동할지
- padding: 필터를 사용하게 되면 원본 이미지의 크기보다 작아지게 되므로 이를 방지하기 위해서 이미지 픽셀 주변에 0으로 채우는 것
- pooling layer
- max pooling: 필터의 크기 안에서 값이 가장 큰 값을 가져오는 형식
- avg pooling: 필터의 크기 안에서 값들의 평균을 가져오는 형식
pooling layer를 사용하는 이유는 다운샘플링 뿐만 아니라 나타나려는 것을 확실히 알 수 있기 때문에 주로 max pooling을 사용한다.
- filter: 커널이라고도 하는데 이미지의 특징을 추출하고(Convolution Layer), 특징을 강화하고 이미지의 크기를 축소(Pooling Layer)한다.
Convolution Neural Network
A Convolutional Neural Network is made up of three main layers:
- The Convolutional Layers
- The Pooling Layers
- The Fully Connected Layers

Convolutional Layers
입력으로서 이미지 텐서를 받고, 이미지 텐서에 특정 수의 컨볼루션 필터(커널)를 적용하고, 렐루 함수를 출력에 적용한다.
이미지에서 패턴과 정보를 추출하는 것이 컨볼루션 레이어의 목적이다.
Pooling Layers
- 이미지의 크기를 줄여서 파라미터와 컴퓨터 연산을 줄일 수 있다.
- 여러 픽셀을 단일 픽셀 값으로 결합해서 네트워크가 일반적이 되도록한다.(과적합 방지)
Fully Connected Layers
flattened image vector(1-D 이미지 텐서)로 만든다. 이 레이어에서 Classification이 진행된다.
최종 CNN 네트워크

CNN을 활용한 모델 정리
AlexNet
- 2012년 도입된 최초의 Large scale CNN 모델
- 8 layers
VGGNet

- 2014년 ImageNet Challenge에서 GoogleLenet 다음으로 성능이 우수하고 강력한 네트워크
- VGG-16, VGG-19 -> 사용한 레이어의 개수에 따라 이름이 나뉜다.
- 8개의 layers는 AlexNet 네트워크를 사용

- [특징] VGG 연구팀에서 깊이가 깊어질수록 성능이 좋아진다는 것을 발견 -> 필터의 크기를 3 * 3으로 고정을 해서 네트워크의 깊이를 깊게 하였다.
GoogleNet

- 2014년 Classification Challenge에서 우승한 네트워크
- 22 Layers 사용(9개의 Inception 모듈)
Inception 모듈

- inception: 더 많은 레이어를 가질수 있도록 함.
bottleneck이란 1*1일 때는 채널이 크고, 3*3 필터를 사용할 때는 채널이 작아지고, 다시 1*1 필터를 사용할 때는 채널이 커져서 이런 거를 병목 현상이라고 한다.
ResNet
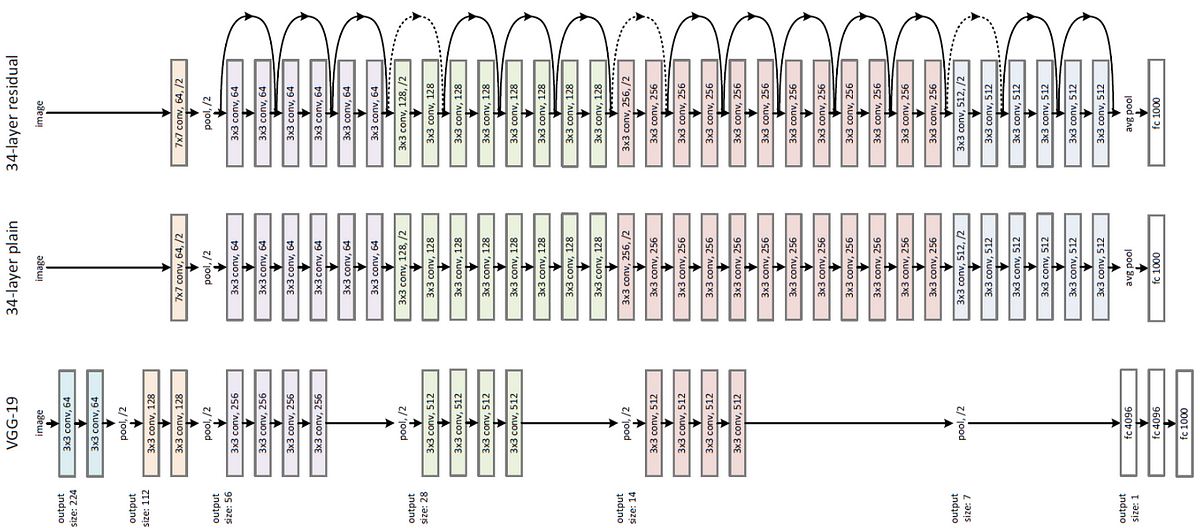

- 깊이가 깊어질수록 경사가 소실되거나 폭발하는 문제를 해결하고자 함. -> Residual block -> conv층을 통과한 F(x)와 conv층을 통과하지 않은 X의 합을 이용
- 152 Layers
Object Detection: 2-stage-detector
물체를 식별하는 classification 문제와 물체의 위치를 찾는 localization 문제를 합한 것인데, 1-stage-detector은 두 가지 task를 동시에 행하는 법이고, 2-stage-detector는 이 두 문제를 순차적으로 행하는 법이다.
1-stage Detector가 비교적으로 빠르지만 정확도가 낮고 2-stage Detector가 비교적으로 느리지만 정확도가 높다.
- 2-stage Detector에는 R-CNN부터 Fast R-CNN, Faster R-CNN같은 R-CNN 계열이 대표적이다.
- 1-stage Detector에는 YOLO(You Only Look Once)계열과 SSD 계열 등이 포함된다.
R-CNN

- Region Proposal: 물체의 영역을 찾음
- Regions of Interest(ROI)라고 부른다. 이 ROI에 대해서 다시 selective search를 통해서 2000개의 ROI를 받는다.
- Convolution Network에 넣기 전에 크기를 조정해서 width와 height를 동일하게 한다. (warp)
- Convolution Network -> feature 추출
- 분류하기 위해서 SVM을 사용(binary classification) + bounding box의 4가지 값도 예측(regression)
Fast R-CNN

R-CNN과 유사하지만 Regions of Interest(ROI)를 개별적으로 처리하는 것이 아니라 전체 이미지에 해당하는 것을 처리한다.
Fast R-CNN에서는 Selective Search 알고리즘 사용하는 것은 R-CNN과 유사하지만 2000개의 crop을 따로따로 CNN에 처리하는 것이 아닌 ConvNet을 처리를 하고 한꺼번에 2000개의 crop을 처리하는 것이므로 R-CNN보다 처리 속도가 빨라진 것이다.
그리고 마지막에 FC 레이어를 추가해서 End-to-End 방식까지 적용할 수 있도록 한다.
문제점
- CPU 상에서 Region Proposal을 사용하기 때문에 여전히 bottleneck 발생
bottleneck이 뭐야,,,?
Faster R-CNN

Fast R-CNN의 문제점을 네트워크 자체가 own region proposals를 예측하도록 하여 해결하였다.
Selective Search 알고리즘을 사용하는 것이 아닌 SPN을 사용해서 모델 자체에서 crop을 뽑아내는 것이므로 모델 성능도 높아지고, 속도도 빨라지고, crop을 하면서 사용한 loss까지 이용할 수 있게 되었다.
2-Stage 방식 정리

-
R-CNN
특징: Selective Search를 통해서 나온 2000개의 Crop을 각각에 대해서 피쳐 맵을 뽑기 뒤해서 CNN를 거쳐 bbox와 category를 예측한다.
문제점: 약 2000개 정도의 Crop이 각각 CNN을 통과해야되다보니 시간이 너무 오래걸린다.
-
Fast R-CNN
특징: Selective Search를 통해서 나온 2000개의 Crop에 대해서 피쳐 맵을 뽑기 위해서 CNN을 한 번만 통과하여 사용한다.
문제점: R-CNN과 마찬가지로 Region Proposal을 CPU를 통해서 진행한다. -> 속도가 느리다.
-
Faster R-CNN
특징: Region Propoal Network(RPN)을 GPU 상에서 진행한다. 이미지를 보고 어느 곳에 object가 있을지를 예측한다.

End-to-End 방식이 가능하다는 것은 FC를 추가하여서 RoI에 대해서 regression과 classification을 한꺼번에 진행을 시킴으로써 같은 loss를 가지고 detection을 진행하기 때문에 정확도가 올라간다.
성능 평가
IOU
두 바운딩 박스가 겹치는 비율을 의미한다. 성능 평가를 위해서도 사용되지만 NMS에서도 많이 사용된다.
NMS(Non Maximum Supperession)
객체 검출에서는 하나의 인스턴스에 하나의 bounding box가 적용되어야 할 때, 가장 많이 겹치는 것을 제외하고 나머지는 없애는 방식이다.
Object Detection VS Segmentation

다음 주
- object detection: YOLO -> 개념 + 실습
- Semantic Segmentation VS Instance Segmentaion
- segmentation: U-Net -> 개념 + 실습
3/26 플젝 미팅 후 ToDo
⬛ 노션 Object Detection 페이지의 5번째 페이지 링크 확인(각 모델의 아이디어 및 구조 파악)
⬛ Semantic Segmentation VS Instance Segmentaion
⬛ Mask R-CNN 실습하기(모듈을 이용해서 모델 사용법 익히기)
⬛ YOLO 기반 segementation도 찾아보기
댓글남기기