
[week 4] VGGNet, GoogLeNet, ResNet
컨볼루션 신경망(Convolution Neural Networks, CNN)
-
완전 연결 네트워크의 문제점으로부터 시작
-
FC의 경우는 매개변수의 폭발적인 증가로 인해 문제 발생
-
FC는 모든 이미지 픽셀을 Flat 하게 펼치기 때문에 근접한 픽셀에 대한 정보 자체가 사라져서 공간 추론의 부족
- 픽셀 사이의 근접성 개념이 완전 연결 계층(Fully-Connected Layer)에서는 손실됨
-
-
합성곱 계층은 입력 이미지가 커져도 튜닝해야 할 매개변수 개수에 영향을 주지 않음
-
또한 그 어떠한 이미지에도 그 차원 수와 상관없이 적용될 수 있음
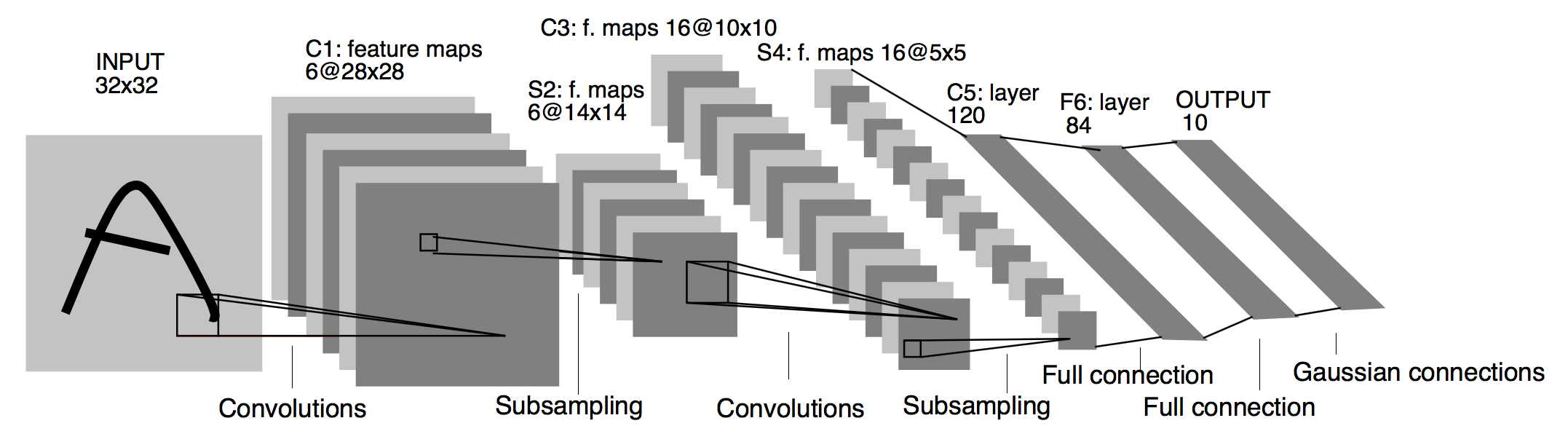
[LeNet-5 구조] [이미지 출처] https://medium.com/@pechyonkin/key-deep-learning-architectures-lenet-5-6fc3c59e6f4
위 그림과 같이 합처서 필터를 이용해서 합성곱을 진행하기 때문에 FC과 달리 공간적인 추리가 가능하다.
컨볼루션 연산 (Convolution Operation)
-
필터(filter) 연산
-
입력 데이터에 필터를 통한 어떠한 연산을 진행
-
필터에 대응하는 원소끼리 곱하고, 그 합을 구함
-
연산이 완료된 결과 데이터를 특징 맵(feature map) 이라 부름
-
-
연산 시각화

[이미지 출처] https://www.researchgate.net/figure/An-example-of-convolution-operation-in-2D-2_fig3_324165524
-
필터(filter)
-
커널(kernel)이라고도 칭함
-
필터의 사이즈는 “거의 항상 홀수” 이다.
-
짝수이면 왼쪽과 오른쪽의 개수도 달라지고, 패딩의 개수도 비대칭이 되기 때문이다.
-
중심위치가 존재, 즉 구별된 하나의 픽셀(중심 픽셀)이 존재
-
-
필터의 학습 파라미터 개수는 입력 데이터의 크기와 상관없이 일정
따라서, 과적합을 방지할 수 있음
-
-
일반적으로, 합성곱 연산을 한 후의 데이터 사이즈는
(n-f+1) * (n-f+1)
n: 입력 데이터의 크기
f: 필터(커널)의 크기

위 예에서 입력 데이터 크기($n$)는 5, 필터의 크기($k$)는 3이므로
출력 데이터의 크기는 $(5 - 3 + 1) = 3$[이미지 출처] https://towardsdatascience.com/intuitively-understanding-convolutions-for-deep-learning-1f6f42faee1
패딩(padding)과 스트라이드(stride)
-
필터(커널) 사이즈과 함께 입력 이미지와 출력 이미지의 사이즈를 결정하기 위해 사용
-
사용자가 결정할 수 있음
패딩
-
입력 데이터의 주변을 특정 값으로 채우는 기법
- 주로 0으로 많이 채움
-
출력 데이터의 크기
(n+2p-f+1) * (n+2p-f+1)
위 그림에서, 입력 데이터의 크기($n$)는 5, 필터의 크기($f$)는 3, 패딩값($p$)은 1이므로
출력 데이터의 크기는 5 + 2* 2 - 4 + 1) = 6
‘valid’ 와 ‘same’
-
‘valid’
- 패딩을 주지 않음
- padding=0
- 0으로 채워진 테두리가 아니라 패딩을 주지 않는다는 뜻!
-
‘same’
-
패딩을 주어 입력 이미지의 크기와 연산 후의 이미지 크기를 같게!
-
만약, 필터(커널)의 크기가 k 이면, 패딩의 크기는 p = {k-1} / {2} (단, stride=1)
-
스트라이드
- 필터를 적용하는 간격을 의미
출력 데이터의 크기
OH = {H + 2P - FH} / {S} + 1
OW = {W + 2P - FW} / {S} + 1
-
입력 크기 : (H, W)
-
필터 크기 : (FH, FW)
-
출력 크기 : (OH, OW)
-
패딩, 스트라이드 : P, S
-
(주의)
- 위 식의 값에서 {H + 2P - FH}{S} 또는 {W + 2P - FW}{S}가 정수로 나누어 떨어지는 값이어야 한다.
- 만약, 정수로 나누어 떨어지지 않으면 패딩, 스트라이드값을 조정하여 정수로 나누어 떨어져야 된다.
풀링(Pooling)
- 필터(커널) 사이즈 내에서 특정 값을 추출하는 과정
맥스 풀링(Max Pooling)
-
가장 많이 사용되는 방법
-
출력 데이터의 사이즈 계산은 컨볼루션 연산과 동일
OH = {H + 2P - FH} / {S} + 1
OW = {W + 2P - FW} / {S} + 1
-
일반적으로 stride=2, kernel_size=2 를 통해
특징맵의 크기를 절반으로 줄이는 역할 -
모델이 물체의 주요한 특징을 학습할 수 있도록 해주며, 컨볼루션 신경망이 이동 불변성 특성을 가지게 해줌
- 예를 들어, 아래의 그림에서 초록색 사각형 안에 있는 2와 8의 위치를 바꾼다해도 맥스 풀링 연산은 8을 추출
-
모델의 파라미터 개수를 줄여주고, 연산 속도를 빠르게 해줌

[이미지 출처] https://cs231n.github.io/convolutional-networks/
평균 풀링(Avg Pooling)
-
필터 내의 있는 픽셀값의 평균을 구하는 과정
-
과거에 많이 사용, 요즘은 잘 사용되지 않는다.
-
맥스풀링과 마찬가지로 stride=2, kernel_size=2 를 통해
특징 맵의 사이즈를 줄이는 역할
[이미지 출처] https://www.researchgate.net/figure/Average-pooling-example_fig21_329885401
케라스 메소드 사용
# 케라스 메소드 -> 고수준 API
from tensorflow.keras.layers import AvgPool2D, MaxPool2D
k, s = (3, 1)
avg_pool = AvgPool2D(pool_size=k, strides=[s, s], padding='valid')
max_pool = MaxPool2D(pool_size=k, strides=[s, s], padding='valid')
컨볼루션 신경망

텐서플로우 저차원 API
class SimpleCNN(tf.keras.layers.Layer):
# 초기화
def __init__(self, num_kernels=32, kernel_size=(3, 3), stride=1):
super().__init__()
self.num_kernels = num_kernels
self.kernel_size = kernels_size
self.stride = stride
# 채널 및 커널, 가중치 초기화
def build(self, input_shape):
input_channels = input_shape[-1]
kernels_shape = (*self.kernel_size, input_channels, self.num_kernels)
glorot_init = tf.initializers.glorot_uniform()
self.kernels = self.add_weight(
name='kernels', shape=kernels_shape, initializer=glorot_init, trainable=True)
self.bias = self.add_weight(name='bias', shape=(self.num_kernels, ), initializer='random_normal', trainable=True)
# layer 생성
def call(self, inputs):
return conv_layer(inputs, self.kernels, self.bias, self.stride)
def conv_layer(x, kernels, bias, s):
z = tf.nn.conv2d(x, kernels, strides=[1, s, s, 1], padding='VALID')
return tf.nn.relu(z + bias)
conv -> relu
케라스 API
# 케라스 API
from tensorflow.keras.layers import Conv2D
s = 1
conv = Conv2D(filters=N, kernel_size=(k, k), strides=s,
padding='valid', activation='relu')
LeNet-5
[이미지 출처] https://medium.com/@pechyonkin/key-deep-learning-architectures-lenet-5-6fc3c59e6f4
-
2014년 ILSVRC 분류 과제에서 2등을 차지했지만, 이 후의 수많은 연구에 영향을 미침
-
특징
-
활성화 함수로
ReLU사용, Dropout 적용 -
합성곱과 풀링 계층으로 구성된 블록과 분류를 위한 완전 연결계층으로 결합된 전형적인 구조
-
인위적으로 데이터셋을 늘림
- 이미지 변환, 좌우 반전 등의 변환을 시도
-
몇 개의 합성곱 계층과 최대-풀링 계층이 따르는 5개의 블록과,
3개의 완전연결계층(학습 시, 드롭아웃 사용)으로 구성 -
모든 합성곱과 최대-풀링 계층에
padding='SAME'적용 -
합성곱 계층에는
stride=1, 활성화 함수로ReLU사용 -
특징 맵 깊이를 증가시킴
-
척도 변경을 통한 데이터 보강(Data Augmentation)
-
-
기여
-
3x3 커널을 갖는 두 합성곱 계층을 쌓은 스택이 5x5 커널을 갖는 하나의 합성곱 계층과 동일한 수용영역(ERF)을 가짐
-
11x11 사이즈의 필터 크기를 가지는 AlexNet과 비교하여,
더 작은 합성곱 계층을 더 많이 포함해 더 큰 ERF를 얻음 -
이와 같이 합성곱 계층의 개수가 많아지면,
매개변수 개수를 줄이고, 비선형성을 증가시킴
-
-
VGG-19 아키텍쳐
- VGG-16에 3개의 합성곱 계층을 추가
from tensorflow.keras import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.datasets import mnist
import numpy as np
class LeNet5(Model):
# 모델 생성
def __init__(self, num_classes):
super(LeNet5, self).__init__()
self.conv1 = Conv2D(6, kernel_size=(5, 5), padding='same', activation='relu')
self.conv2 = Conv2D(16, kernel_size=(5, 5), activation='relu')
self.max_pool = MaxPooling2D(pool_size=(2, 2))
self.flatten = Flatten()
self.dense1 = Dense(120, activation='relu')
self.dense2 = Dense(84, activation='relu')
self.dense3 = Dense(num_classes, activation='softmax')
def call(self, input_data):
x = self.max_pool(self.conv1(input_data))
x = self.max_pool(self.conv2(x))
x = self.flatten(x)
x = self.dense3(self.dense2(self.dense1(x)))
return x
LeNet5 클래스를 보면 Convolution 층 -> MaxPooling -> Convlution 층 -> MaxPooling -> Flatten -> FC -> FC -> FC 구조로 되어 있다.
VGGNet

# VGGNet
import tensorflow as tf
vgg_net = tf.keras.applications.VGG16(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
vgg_net.summary()
>>>
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
flatten (Flatten) (None, 25088) 0
fc1 (Dense) (None, 4096) 102764544
fc2 (Dense) (None, 4096) 16781312
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
그림과 똑같이 층을 구성하고 있음을 확인할 수 있다.
googleNet

Inception 모듈

# 원시 버전의 인셉션 블록
from tensorflow.keras.layers import Conv2D, MaxPooling2D, concatenate
def naive_inception_block(prev_layer, filter=[64, 128, 32]):
conv1x1 = Conv2D(filters[0], kernel_size=(1, 1), padding='same', activation='relu')(prev_layer)
conv3x3 = Conv2D(filters[1], kernel_size=(3, 3), padding='same', activation='relu')(prev_layer)
conv5x5 = Conv2D(filters[2], kernel_size=(5, 5), padding='same', activation='relu')(prev_layer)
max_pool = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(prev_layer)
return concatenate(conv1x1, conv3x3, conv5x5, max_pool)
GoogleNet 케라스 모델
# 케라스 모델에서 인셉션 모델 사용하기
inceptionV3_net = tf.keras.applications.InceptionV3(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
inceptionV3_net.summary()
# mixed가 인셉션인 것을 확인할 수 있다.
>>>
Model: "inception_v3"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 299, 299, 3 0 []
)]
conv2d_98 (Conv2D) (None, 149, 149, 32 864 ['input_3[0][0]']
)
batch_normalization_94 (BatchN (None, 149, 149, 32 96 ['conv2d_98[0][0]']
ormalization) )
activation_94 (Activation) (None, 149, 149, 32 0 ['batch_normalization_94[0][0]']
)
conv2d_99 (Conv2D) (None, 147, 147, 32 9216 ['activation_94[0][0]']
)
batch_normalization_95 (BatchN (None, 147, 147, 32 96 ['conv2d_99[0][0]']
ormalization) )
activation_95 (Activation) (None, 147, 147, 32 0 ['batch_normalization_95[0][0]']
)
conv2d_100 (Conv2D) (None, 147, 147, 64 18432 ['activation_95[0][0]']
)
batch_normalization_96 (BatchN (None, 147, 147, 64 192 ['conv2d_100[0][0]']
ormalization) )
activation_96 (Activation) (None, 147, 147, 64 0 ['batch_normalization_96[0][0]']
)
max_pooling2d_7 (MaxPooling2D) (None, 73, 73, 64) 0 ['activation_96[0][0]']
conv2d_101 (Conv2D) (None, 73, 73, 80) 5120 ['max_pooling2d_7[0][0]']
batch_normalization_97 (BatchN (None, 73, 73, 80) 240 ['conv2d_101[0][0]']
ormalization)
activation_97 (Activation) (None, 73, 73, 80) 0 ['batch_normalization_97[0][0]']
conv2d_102 (Conv2D) (None, 71, 71, 192) 138240 ['activation_97[0][0]']
batch_normalization_98 (BatchN (None, 71, 71, 192) 576 ['conv2d_102[0][0]']
ormalization)
activation_98 (Activation) (None, 71, 71, 192) 0 ['batch_normalization_98[0][0]']
max_pooling2d_8 (MaxPooling2D) (None, 35, 35, 192) 0 ['activation_98[0][0]']
conv2d_106 (Conv2D) (None, 35, 35, 64) 12288 ['max_pooling2d_8[0][0]']
batch_normalization_102 (Batch (None, 35, 35, 64) 192 ['conv2d_106[0][0]']
Normalization)
activation_102 (Activation) (None, 35, 35, 64) 0 ['batch_normalization_102[0][0]']
conv2d_104 (Conv2D) (None, 35, 35, 48) 9216 ['max_pooling2d_8[0][0]']
conv2d_107 (Conv2D) (None, 35, 35, 96) 55296 ['activation_102[0][0]']
batch_normalization_100 (Batch (None, 35, 35, 48) 144 ['conv2d_104[0][0]']
Normalization)
batch_normalization_103 (Batch (None, 35, 35, 96) 288 ['conv2d_107[0][0]']
Normalization)
activation_100 (Activation) (None, 35, 35, 48) 0 ['batch_normalization_100[0][0]']
activation_103 (Activation) (None, 35, 35, 96) 0 ['batch_normalization_103[0][0]']
average_pooling2d_10 (AverageP (None, 35, 35, 192) 0 ['max_pooling2d_8[0][0]']
ooling2D)
conv2d_103 (Conv2D) (None, 35, 35, 64) 12288 ['max_pooling2d_8[0][0]']
conv2d_105 (Conv2D) (None, 35, 35, 64) 76800 ['activation_100[0][0]']
conv2d_108 (Conv2D) (None, 35, 35, 96) 82944 ['activation_103[0][0]']
conv2d_109 (Conv2D) (None, 35, 35, 32) 6144 ['average_pooling2d_10[0][0]']
batch_normalization_99 (BatchN (None, 35, 35, 64) 192 ['conv2d_103[0][0]']
ormalization)
batch_normalization_101 (Batch (None, 35, 35, 64) 192 ['conv2d_105[0][0]']
Normalization)
batch_normalization_104 (Batch (None, 35, 35, 96) 288 ['conv2d_108[0][0]']
Normalization)
batch_normalization_105 (Batch (None, 35, 35, 32) 96 ['conv2d_109[0][0]']
Normalization)
activation_99 (Activation) (None, 35, 35, 64) 0 ['batch_normalization_99[0][0]']
activation_101 (Activation) (None, 35, 35, 64) 0 ['batch_normalization_101[0][0]']
activation_104 (Activation) (None, 35, 35, 96) 0 ['batch_normalization_104[0][0]']
activation_105 (Activation) (None, 35, 35, 32) 0 ['batch_normalization_105[0][0]']
mixed0 (Concatenate) (None, 35, 35, 256) 0 ['activation_99[0][0]',
'activation_101[0][0]',
'activation_104[0][0]',
'activation_105[0][0]']
==================================================================================================
Total params: 23,851,784
Trainable params: 23,817,352
Non-trainable params: 34,432
__________________________________________________________________________________________________
ResNet
-
네트워크의 깊이가 깊어질수록 경사가 소실되거나 폭발하는 문제를 해결하고자 함
-
병목 합성곱 계층을 추가하거나 크기가 작은 커널을 사용
-
152개의 훈련가능한 계층을 수직으로 연결하여 구성
-
모든 합성곱과 풀링 계층에서 패딩옵셥으로 “SAME”, stride=1 사용
-
3x3 합성곱 계층 다음마다 배치 정규화 적용, 1x1 합성곱 계층에는 활성화 함수가 존재하지 않음
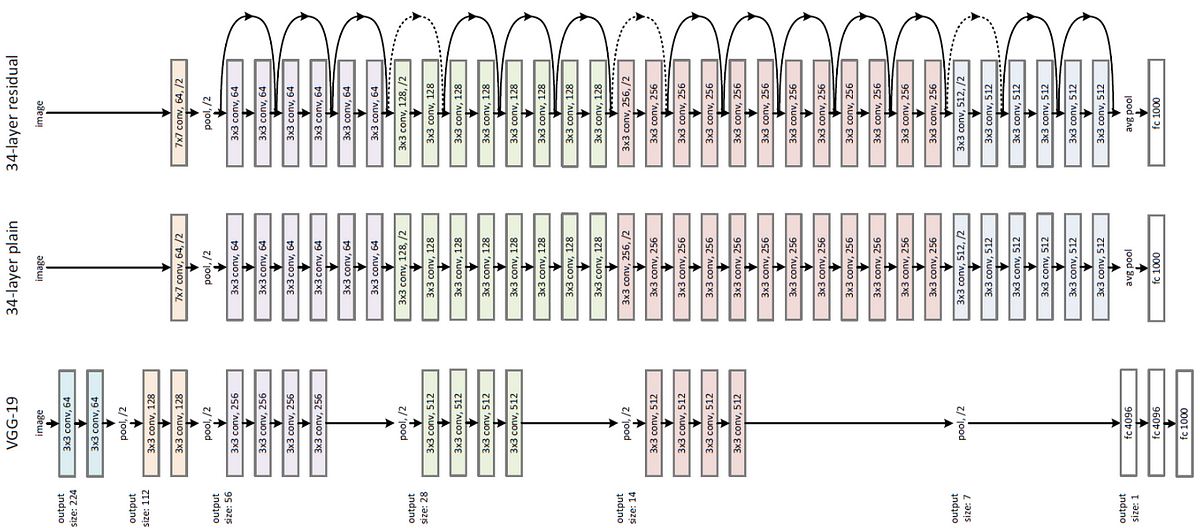
[이미지 출처] https://towardsdatascience.com/review-resnet-winner-of-ilsvrc-2015-image-classification-localization-detection-e39402bfa5d8
# ResNet - 잔차 네트워크
from tensorflow.keras.layers import Activation, Conv2D, BatchNormalization, add
def residual_block_basic(x, filters, kernel_size, strides=1):
conv_1 = Conv2D(filters=filters, kernel_size=kernel_size, padding='same', strides=strides)(x)
bn_1 = BatchNormalization(axis=-1)(conv_1)
act_1 = Activation('relu')(bn_1)
conv_2 = Conv2D(filters=filters, kernel_size=kernel_size, padding='same', strides=strides)(act_1)
residual = BatchNormalization(axis=-1)(conv_2)
shortcut = x if strides == 1 else Conv2D(filters, kernel_size=1, padding='valid', strides=strides)(x)
return Activation('relu')(add[shortcut, residual])
# 케라스 모델에서 레즈넷 사용하기
resnet50 = tf.keras.applications.ResNet50(
include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000
)
resnet50.summary()
>>>
Model: "resnet50"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_4 (InputLayer) [(None, 224, 224, 3 0 []
)]
conv1_pad (ZeroPadding2D) (None, 230, 230, 3) 0 ['input_4[0][0]']
conv1_conv (Conv2D) (None, 112, 112, 64 9472 ['conv1_pad[0][0]']
)
conv1_bn (BatchNormalization) (None, 112, 112, 64 256 ['conv1_conv[0][0]']
)
conv1_relu (Activation) (None, 112, 112, 64 0 ['conv1_bn[0][0]']
)
pool1_pad (ZeroPadding2D) (None, 114, 114, 64 0 ['conv1_relu[0][0]']
)
pool1_pool (MaxPooling2D) (None, 56, 56, 64) 0 ['pool1_pad[0][0]']
conv2_block1_1_conv (Conv2D) (None, 56, 56, 64) 4160 ['pool1_pool[0][0]']
...
Total params: 25,636,712
Trainable params: 25,583,592
Non-trainable params: 53,120
VGGNet으로 ImageNet 학습하기
VGG 연구팀은 총 6개의 구조를 만들고 성능을 비교한 결과 깊어질수록 성능이 좋아진다는 것을 발견했다.

인풋으로는 224 x 224 x 3 이미지를 입력받을 수 있다. 16개의 층을 지난 후 softmax 함수로 활성화 된 출력값들은 1000개의 뉴런으로 구성된다. -> 다운이 너무 오래 걸려서,,,, 다운 중,,,
ResNet 50

오른쪽 그림이 ResNet50이 구조에 맞는 Residual Block의 구조이다.
-
Conv 1x1([1, 1, 64] block에 해당)
- convolution - batch normalization - relu를 거치도록 작성
-
Conv 3x3([3, 3, 64] block에 해당)
- 필터의 크기를 1에서 3으로 바꾸었을 뿐, 그 외에는 1x1과 동일
-
Residual Block Function 완성([1, 1, 256] block에 해당)
-
- F(x)에 입력값 x가 합쳐져야 하는 경우
- input x가 F(x)와 같은 채널을 가지도록 convolution layer 하나 더 준비.
- F(x)에 입력값 x가 합쳐져야 하는 경우
-
- Residual block이 아닌 경우
- 추가적인 convolution layer 준비할 필요가 없음.
- Residual block이 아닌 경우
-
ResNet 50 Layers

위의 residual block을 바탕으로 한 ResNet50 구조 -> 50개의 층을 가지고 각각의 conv에 있는 []가 residual block이다.

downsample 여부를 이용해서 끝에 f(x) + x 나타나는지 확인
# (in_ch, middle_ch, out_ch, downsample)
self.layer3 = nn.Sequential(
ResidualBlock(256, 128, 512, False),
ResidualBlock(512, 128, 512, False),
ResidualBlock(512, 128, 512, False),
ResidualBlock(512, 128, 512, True)
)
Layer 1
7x7 conv + maxPooling 층까지
class ResNet50_layer4(nn.Module):
def __init__(self, num_classes=10):
super(ResNet50_layer4, self).__init__()
# Layer 1
# (in_channels, out_channels, kernel_size, stride, padding)
# MaxPool2d 의미
self.layer1 = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 1)
)
Layer 2
self.layer2 = nn.Sequential(
ResidualBlock(64, 64, 256, False),
ResidualBlock(256, 64, 256, False),
ResidualBlock(256, 64, 256, True)
)
Layer 3
self.layer3 = nn.Sequential(
ResidualBlock(256, 128, 512, False),
ResidualBlock(512, 128, 512, False),
ResidualBlock(512, 128, 512, False),
ResidualBlock(512, 128, 512, True)
)
Layer 4
self.layer4 = nn.Sequential(
ResidualBlock(512, 256, 1024, False),
ResidualBlock(1024, 256, 1024, False),
ResidualBlock(1024, 256, 1024, False),
ResidualBlock(1024, 256, 1024, False),
ResidualBlock(1024, 256, 1024, False),
ResidualBlock(1024, 256, 1024, True)
)
Layer 5
self.layer5 = nn.Sequential(
ResidualBlock(1024, 512, 2048, False),
ResidualBlock(2048, 512, 2048, False),
ResidualBlock(2048, 512, 2048, False)
)
Layer 6
self.fc = nn.Linear(2048, 10)
self.avgpool = nn.AvgPool2d((2, 2), stride=0)
댓글남기기